what is this
matryoshka representation learning is widely used recently to train text encoders due to its benefits of being able to shrink embedding sizes posthoc. a lot of strong open-weight text encoders are now trained with, as well as, proprietary apis. however, there is almost no study (afaik) which analysis models trained with mrl, and it bothers me a bit.
this is a working note where i write down some stuff i explored regarding matryoshka embeddings. there are some experimental results here but they are done in small scale and quickly so don’t take them too seriously. it’s mostly random stuff, if you find errors or something unclear, feel free to reach out.
notes
training pairs of mrl and non-mrl encoders
there are many mrl models but there are not many pairs of models that are trained from the same plm but one with standard way and another with mrl. this makes fair analysis difficult, so i started to train small encoders in this setup. hopefully, i can test questions listed below using these models.
the code i used to train models is here and i am putting trained models here.
questions
some questions i have regarding mrl encoders. i am first training models.
do we lose something if we train with mrl?
mrl is simple enough so the implementation is simple and not so much of compute overhead. but does it really come for free?
differences in geometric properties of embeddings
what happens to embeddings as vectors if we do mrl? i want to measure isotropy, dimensional collapse, outlier dimensions, intrinsic dimensions in embeddings produced by mrl encoders.
small test
i used bert-based models i trained , computed embeddings of some documents (texts from this dataset), and computed three metrics, isoscore (↑), uniform loss (↓), correlation between dimensions (↓). they are often used to assess quality of embeddings.
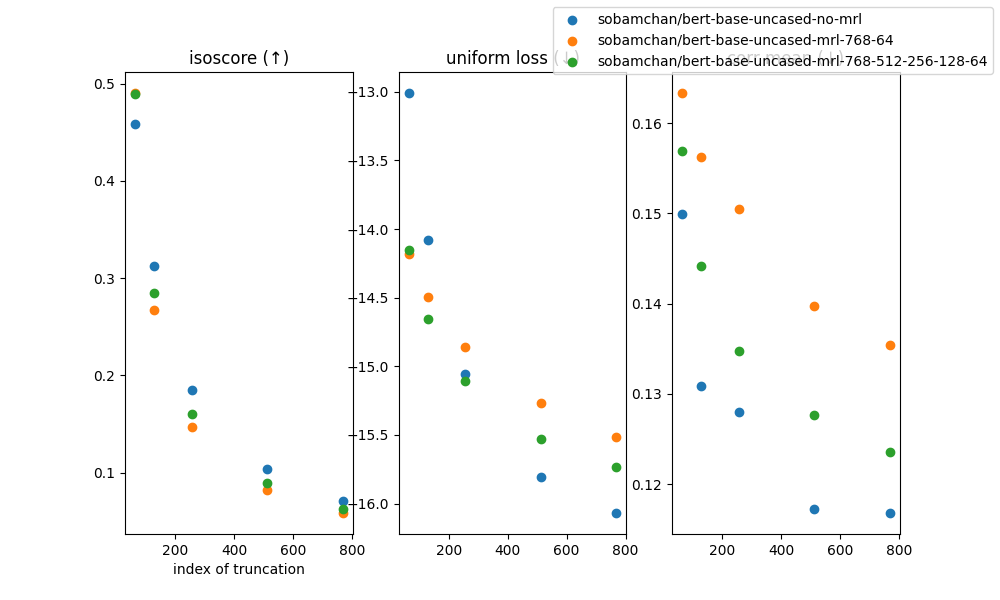
on x-axes, the most right points represent the embeddings without any truncation. as it goes to left, more dimensions are removed from the last (or right) of embeddings.
this is a very small quick test but from this little experiment, we can see following things
- isoscore (left fig):
- until the hardest truncation, non-mrl model seems to use the embedding space better than mrl models
- between two mrl variants, mrl with only one cut point (mrl-768-64) seems to have worse space usage than the model with more cut points (mrl-768-512-256-128-64)
- uniform loss (middle fig): mrl model gets better than non-mrl faster compared to when measure by isoscore but we see similar patters
- correlation (right fig):
- differently from two metrics above which measure isotropy (anisotropy), non-mrl model has better correlation between dimensions (i.e., less correlations, less redundant features) with all truncation level
differences in training dynamics
are there differences during training like how losses change, how the parameters get updated between non-mrl vs mrl?
differences in model weights
are models (non-mrl, mrl) different if we see their weights? can we use model diffing to see this?